Российские языковые модели (NLP) для бизнеса
Обновлено: 15.11.2024
Примеры российских систем искусственного интеллекта для обработки естественного (русского) языка - представлены ниже.
Пользователи, которые искали NLP, потом также интересовались следующими продуктами:

См.также: Топ 10: ИИ платформы
Пользователи, которые искали NLP, потом также интересовались следующими продуктами:
См.также: Топ 10: ИИ платформы
2024. Авито саммаризирует отзывы с помощью ИИ
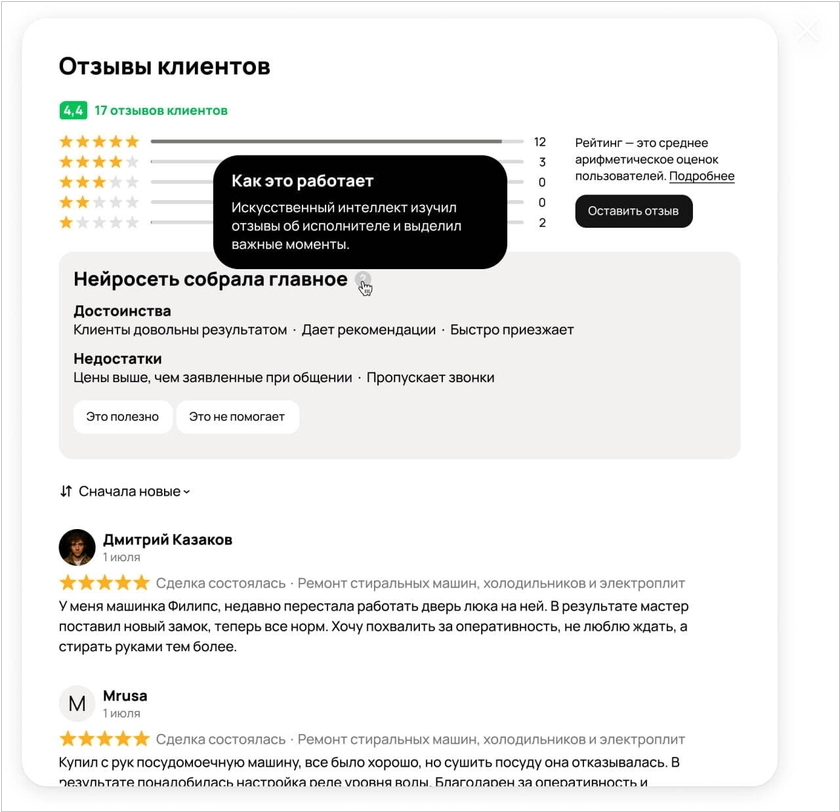
Главный российский сервис объявлений Авито обучил собственную большую языковую модель (LLM) анализировать отзывы и составлять короткую выжимку с выводами, чтобы пользователи могли быстро понять общую оценку этого товара или услуги. Для начала эту функцию добавили на страницы исполнителя различных услуг. ИИ умеет выделять ключевые преимущества и недостатки конкретного исполнителя на основании того, что пишут о нем клиенты. Компания планирует масштабировать новую функцию на другие категории и вертикали сервиса, одновременно целенаправленно улучшать модель.
2024. Т-Банк выпустил маленькую русскоязычную языковую модель T-lite
Центр искусственного интеллекта Т-Банка открыл доступ к своей большой языковой модели T-lite. Весовая категория T-lite — 7-8 млрд параметров. У Сбера (главного конкурента) год назад вышла модель ruGPT-3.5 с 13 млрд параметров. Но разработчики Т-Банка считают, что не в параметрах счастье, и что в бенчмарках модель показывает сравнимые результаты с большими моделями в решении бизнес-задач на русском языке, используя всего 3% вычислительных ресурсов, которые обычно требуются. Это особенно актуально сейчас, когда в России усиливается дефицит центров обработки данных. Из Китая импортировать сервера становится все сложнее, а отбирать сервера у Ютюба долго не получится. С помощью T-lite компании смогут создавать экономные LLM-приложения для собственного использования без передачи данных третьим лицам. Например, ассистентов поддержки, которые могут автоматически обрабатывать запросы клиентов.
2024. Яндекс разрабатывает мультимодальную нейросеть, но до уровня ChatGPT далеко
По данным Коммерсанта, Яндекс разрабатывает новую модель SpeechGPT, которая станет мультимодальной и сможет выполнять задачи на стыке текста и звука. Сейчас компания нанимает в свою команду специалистов в области машинного обучения для этого проекта. В описании вакансии на сайте компании указано, что новая модель «умеет воспринимать текст и звук, отвечать текстом и звуком, решать разные задачи на стыке текста и звука». Про работу с визуальной информацией - пока не упоминается (хотя у Яндекса есть нейросеть Шедеврум). Эксперты полагают, что модель будет представлена в ближайшие месяцы. SpeechGPT постепенно будут встраивать в уже существующие сервисы, связанные с клиентами и партнерами компании. Однако вряд ли новый генеративный продукт сможет конкурировать с возможностями Gemini или ChatGPT, поскольку на создание подобных сервисов необходимы миллиарды долларов.
2023. Вышла новая версия нейросетевой модели от Сбера - GigaChat
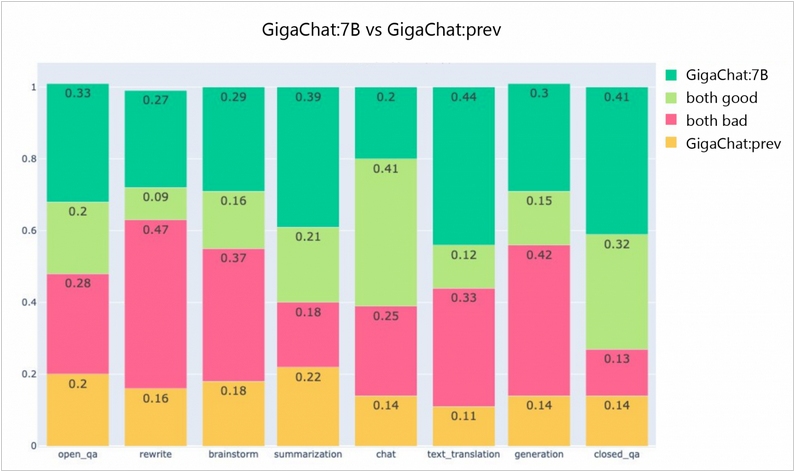
Разработчики сберовской языковой модели GigaChat говорят, что с новой версией им удалось добиться качественного прорыва, расширить максимальную длину входного запроса модели и проделать множество других улучшений. Для оценки прорыва они использовали один из самых популярных тестов для оценки больших языковых моделей является MMLU. Он представляет собой набор закрытых вопросов (когда нужно выбрать один из предложенных вариантов) на 57 тем (математика, физика, экономика и другие). Самая продвинутая на сегодняшний день модель GPT-4 от OpenAI показывает результат в 86,4%. Показатель новой версии GigaChat 7B - 51,49%. Значительно улучшились навыки суммаризации текстов, ответов на вопросы, генерации идей и перевода. Разработчики также провели SBS-сравнение с моделью ChatGPT (gpt3.5-turbo) и зафиксировали рывок до 43/57 против 33/67 у предыдущей версии.
2023. YandexGPT 2 - большое обновление языковой модели Яндекса
Яндекс представил новую версию своей альтернативы ChatGPT - языковой модели YandexGPT 2. Сейчас YandexGPT 2 доступна на ya.ru — главной странице Яндекса — в навыке «Алиса, давай придумаем». Навык работает также в приложении Яндекс, Яндекс Браузере, на Яндекс Станции и телевизорах с Алисой. YandexGPT 2 помогает структурировать информацию, генерировать идеи, писать тексты и многое другое. Новая модель отвечает лучше старой в 67% случаев, а в некоторых сценариях побеждает с ещё бо́льшим перевесом. Этого результата разработчики добились благодаря улучшениям на каждом этапе обучения модели, но ключевое изменение — новый pretrain.

2023. Сбер открывает доступ к нейросетевой модели ruGPT-3.5

Сбер объявил о релизе в открытый доступ нейросетевой модели, которая лежит в основе сервиса GigaChat. Количество параметров в языковой модели ruGPT-3.5 составляет 13 миллиардов. Это декодерная модель, которая может использоваться для решения широкого круга NLP задач. Модель была обучена в два этапа. Сначала она обучалась около полутора месяцев на 300 Гб данных, состоящих из книг, энциклопедийных и научных статей, социальных ресурсов и других источников. Затем мы провели дообучение («дотрейн») на 110 Гб данных, включающих код из датасета The Stack, юридические документы и обновленные тексты википедий.
2023. Сбер представил русскоязычный аналог ChatGPT
Команда Sber AI под руководством Татьяны Шавриной открыла (пока очень ограниченный) доступ к GigaChat - русскоязычному аналогу ChatGPT. Он основан на нейросети ruGPT, которая построена на архитектуре GPT от OpenAI и до сих пор считалась лучшей языковой моделью, созданной российскими компаниями. Однако, в случае с языковой нейросетью, - не достаточно скопировать технологии, нужно еще сформировать корпус текстов для ее обучения и масштабировать ее платформу. И здесь, конечно, GigaChat пока очень проигрывает (13 млрд параметров против 175 млрд у GPT3). Кроме того, чисто теоретически, количество текстов/знаний на русском языке на порядки меньше количества текстов/знаний на английском. Но для наполнения ру-сайтов водой, написания рекламных текстов и спам-писем - GigaChat вполне подойдет и сделает это более "грамматично" чем ChatGPT. За счет интеграции с сетью Kandinsky - можно в том же чате генерировать изображения по описанию. Пока все это доступно в закрытой группе Telegram, в которую пускают только избранных.
2022. Яндекс запустил ИИ генератор текстов для интернет-магазинов и рекламы
Яндекс запустил онлайн генератор текстов Балабоба. Пользователю можно написать одно-два слова на русском или английском языках и выбрать один из стилей — и Балабоба создаст осмысленный текст на любую тему, похожий на тексты из интернета, на которых училась модель. Например, таким образом можно генерировать описание для товаров в интернет-магазине, создать текст для рекламы и т. п. Сервис генерирует тексты с помощью языковой модели Яндекса YaLM, которая решает задачи, связанные с обработкой естественного языка. Например, модели YaLM помогают Алисе поддерживать беседу, определяют темы вопросов в «Кью», улучшают описания заказов на «Услугах», генерируют карточки для быстрых ответов в поисковике. Также языковые модели YaLM ищут ключевые моменты видео, генерируют рекламные объявления и описания сайтов (сниппеты).
2022. Яндекс выложил GPT-подобную нейросеть YaLM 100B в свободный доступ

Яндекс выложил в свободный доступ свою самую большую модель YaLM на 100 млрд параметров. Она обучалась 65 дней на 1,7 ТБ текстов из интернета, книг и множества других источников с помощью 800 видеокарт A100. Модель и дополнительные материалы опубликованы на Гитхабе под лицензией Apache 2.0, которая допускает применение как в исследовательских, так и в коммерческих проектах. Сейчас это самая большая в мире GPT-подобная нейросеть в свободном доступе как для английского, так и для русского языков.
2021. Языковые модели от SberDevices стали лучшими в мире по пониманию текстов на русском языке
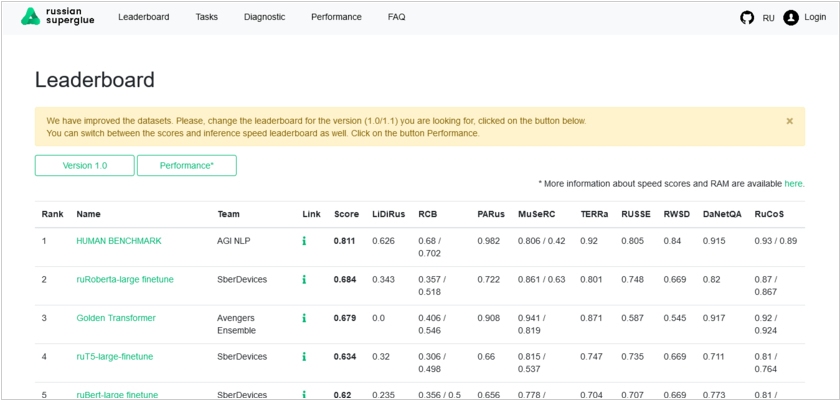
Разработанная SberDevices текстовая модель finetune стала лучшей по пониманию текста в соответствии с оценкой главного русскоязычного бенчмарка для оценки больших текстовых моделей Russian SuperGLUE, уступая по точности только человеку. Оценка общего понимания языка начинается в рейтинге с набора тестов, отражающих различные языковые явления — диагностического датасета. Он отражает лингвистические феномены языка и показывает, насколько модель ruRoberta-large finetune понимает те или иные его особенности. Высокий скор (LiDiRus) говорит о том, что модель не просто запомнила задания или угадывает результат, а выучивает особенности и осваивает разнообразие феноменов русского языка.
2021. Яндекс разработал языковую модель для генерации текстов
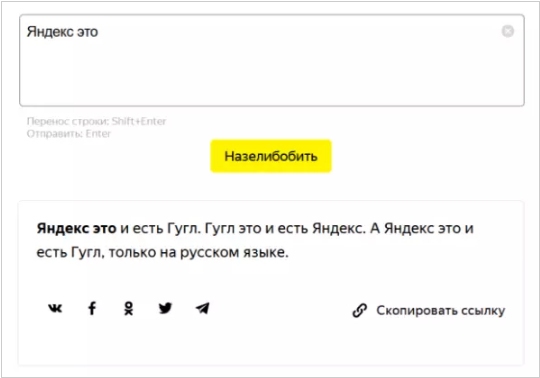
Яндекс представил нейросетевой языковой алгоритм генерации текстов YaLM и сервис «Зелибоба» на его основе. Сервис умеет подбирать следующее слово в предложении и благодаря этому писать небольшие тексты на основе нескольких слов, введенных пользователем. Языковая модель, лежащая в основе «Зелибобы», была обучена на нескольких терабайтах русскоязычных текстов, в том числе статьях Википедии, новостных заметках и постах в социальных сетях. Через «Зелибобу» можно было создавать тексты в разных стилях: новостной заметки, анекдота, рекламного слогана, короткой истории и других.
2020. Одноклассники предложили бизнесу сервис для анализа текстов, фотографий и видео с помощью нейросетей
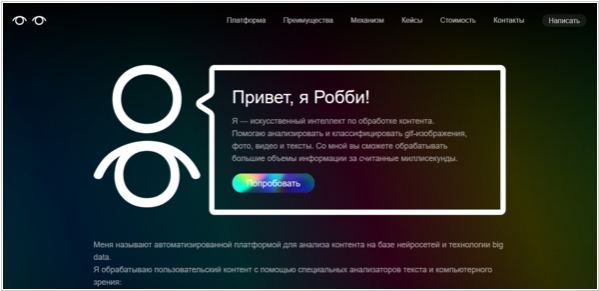
Соцсеть Одноклассники предтавила автоматизированную платформу Робби для анализа материалов на сайте с помощью нейросетей и технологии big data. Сервис распознаёт текст, объекты на фотографиях, видео и GIF-анимации и умеет находить дубли, ссылки, телефонные номера на изображениях, спам в текстах и так далее. Например, интернет-магазины могут с помощью «Робби» автоматически обрабатывать отзывы клиентов, а видеосервисы — определять в роликах и стримах запрещённые материалы и рекламу. Робби работает через API и подойдёт как для крупного бизнеса, так и для небольших компаний, отмечают в соцсети. Стоимость обработки контента с помощью платформы — от 10 тысяч рублей в месяц.
2019. Компания Айтеко разработала чат-бота для общения с клиентами
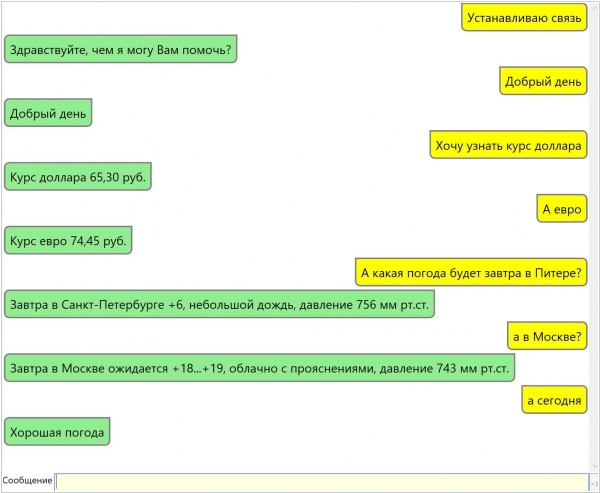
Центр когнитивных технологий Айтеко создал чат-бота для контакт-центров, сервисных компаний, служб продаж. С помощью него клиенты могут оформить заказ товара или услуги, оставить сервисную заявку, получить интересующую информацию. По комплексному сценарию чат-бот может собирать первичные данные клиента и затем переводить его на оператора. Решение может использоваться как самостоятельный продукт и интегрироваться в сложные комплексные сценарии обработки входящих сообщений. Интеграция с внешними сервисами делает доступным обмен текстовыми сообщениями в привычном пользователю интерфейсе, например, в корпоративном мессенджере; общение происходит на привычном для пользователя естественном языке. Чат-бот реализован на базе собственной разработки компании «Айтеко» в области искусственного интеллекта – решения Smartsel.