Российские нейросети для генерации устной речи на русском языке
Обновлено: 14.07.2025
Примеры российских систем и сервисов для генерации речи - представлены ниже.
2025. Яндекс открыл сервис быстрого синтеза речи Brand Voice Lite
На платформе Yandex Cloud (в составе Yandex SpeechKit) появился сервис Brand Voice Lite для быстрого синтеза речи Brand Voice Lite. Теперь компаниям достаточно загрузить в сервис 20-40 минут записи речи диктора, чтобы создать уникальный голос своего бренда. Его можно использовать для создания персонализированных голосовых ботов в контакт-центрах, а также для озвучки подкастов, образовательных материалов и других креативных бизнес-проектов. Создание голоса стоит от 9000 руб. Хостинг модели и обработка запросов тарифицируются отдельно в соответствии с действующими тарифами. Проверка аудиозаписей при создании обучающего датасета в браузере оплачивается отдельно по правилам тарификации асинхронного распознавания SpeechKit.
2023. Сбер выпустил приложение SaluteSpeech для синтеза и распознавания речи в аудио
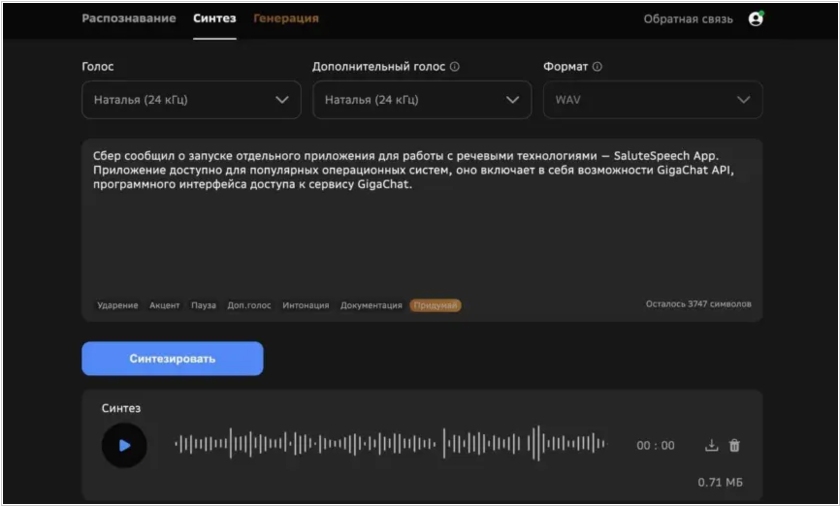
Сбер выпустил десктоп-приложение SaluteSpeech App для синтеза и распознавания речи в аудио. Оно работает на Windows и Mac. В приложении есть два раздела. «Распознавание» — для текстовой расшифровки голосовых файлов. «Синтез» — для озвучивания текста с возможностью настраивать паузы и ударения. Синтезировать текст можно разными голосами из семи вариантов на русском и английском языках. В приложение встроен GigaChat API, поэтому пользователь может загрузить короткие тезисы, нейросеть по ним подготовит текст для озвучивания. Также с помощью GigaChat в приложении можно сделать короткую выжимку длинного текста, а после озвучить материал. Приложение бесплатное, но чтобы начать работу, надо подключить сервис SaluteSpeech. Его минимальная стоимость за месяц использования — 600 рублей. Есть бесплатный тариф для физлиц Freemium, по нему доступно 100 минут распознавания и 200 тысяч символов синтеза в месяц.
2023. Yandex Cloud запустил сервис генерации голосов для виртуальных операторов колл-центров
На облачной платформе Yandex Cloud появился сервис Brand Voice Call Center. Он синтезирует речь по одной фразе и передаёт интонацию реального человека. Алгоритм способен обработать аудиошаблон и создать на его основе сотни других реплик. При этом его можно научить обращаться к собеседнику по имени или согласовывать адреса и набор товаров в заказе. В сгенерированных фразах также можно менять отдельные слова. Речь, сгенерированная с помощью Brand Voice Call Center, звучит естественно и передаёт детали речи человека из шаблона: интонации, изменения громкости. А в качестве образцов можно использовать записи реальных разговоров операторов колл-центров. Клиенты сервиса должны будут платить только за запросы — бюджет на обучение и поддержку алгоритма не потребуется.
2021. Aimyvoice - сервис для покупки и создания синтезированных голосов
Разработчик разговорных ИИ-технологий Just AI запустил сервис Aimyvoice для покупки и создания синтезированных голосов. Голоса можно использовать для озвучивания видеороликов, ассистентов, ботов, служб поддержки и другого. Можно выбрать голос из каталога или синтезировать собственный и зарабатывать на его использовании. В каталоге доступно 18 вариантов — дикторские, мужские, женские и детские. Например, есть голос актрисы озвучки Татьяны Литвиновой, голоса персонажей и известных личностей, например, Деда Мороза и Ленина. Чтобы синтезировать собственную голосовую модель, надо загрузить аудиофайл, где будет от пяти часов записи живой речи.
2021. Яндекс запустил сервис для создания фирменных голосов для бизнеса
Платформа Yandex.Cloud представила сервис Yandex SpeechKit Brand Voice для создания фирменных голосов для виртуальных помощников, автоматизации колл-центра, проведения опросов, приёма входящих и исходящих звонков клиентам и других потребностей бизнеса. Сервис не генерирует речь просто из текста, он берет за основу голос реального человека и синтезирует новый. Он может персонализировать речь: например, добавить обращение, дату, номер заказа и другое, но звучит естественно. Создание фирменного голоса занимает месяц, а стоимость хостинга его ML-модели в облаке Яндекса - 150 тысяч рублей в месяц.
2021. Яндекс.Маркет начал использовать нейросеть для написания итоговых отзывов
Отзывы на товары читать, конечно, интересно, но иногда их так много, что на прочтение всех можно потратить больше времени, чем стоит товар. Поэтому разработчики Яндекс.Маркета придумали (с помощью нейросети) формировать умные/собирательные отзывы, написанные по комментариям покупателей. Такие отзывы состоят из двух частей: подробного комментария о товаре и набора ключевых характеристик, которые чаще всего отмечают пользователи, — например, для ноутбука - качество сборки, дизайн и удобство, уровень шума. Первое время перед попаданием на платформу, такой отзыв будет проверять человек.
2021. Сбер представил сервис речевых технологий для бизнеса
Сбер запустил сервис SmartSpeech, который позволит бизнесу без специального оборудования подключать к своим системам речевые технологии - например, в интерактивном голосовом меню, автоответчике, чатах и других голосовых интерфейсах. SmartSpeech можно использовать на сайтах, в приложениях и «умных» устройствах для озвучивания контента и команд или голосового ввода. Для этого достаточно загрузить текст, и робот сам прочтёт его вслух — заранее записывать речь не придётся. Сервис распознаёт и синтезирует речь, а также способен использовать «подсказки», чтобы понимать пользователя в зависимости от конкретной ситуации. До конца 2021 года сервис можно подключить бесплатно.
2020. Speech Robot - робот для телефонных звонков вместо call-центра
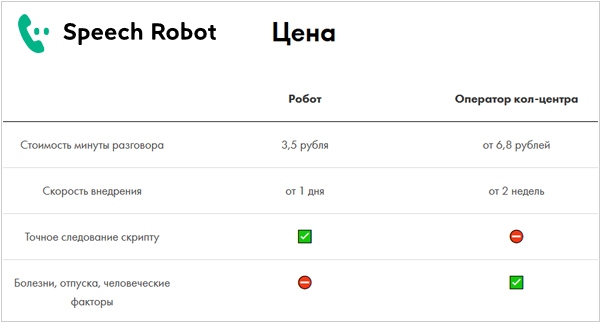
Speech Robot - новый сервис для автоматизации кол-центра. Его можно использовать для приема и подтверждения заказов, холодных звонков, информирования о доставке, маркетинговых опросов, проведения первичных собеседований. Робот делает звонки быстрее человека и стоит дешевле, это позволяет сокращать количество людей в кол-центре благодаря автоматизации рутинных задач. Есть готовые сценарии для информирования, оценки качества обслуживания, подтверждения заказа в интернет магазине, согласования даты и времени доставки. Можно связать с CRM системой. Тарификация - поминутная: минута исходящего разговора - 3,5 рубля, входящего - 70 копеек, распознавание речи - 75 копеек.
2019. Сбербанк купил знаменитого разработчика систем распознавания голоса

Сбербанк купил 51% акций компании Центр Речевых Технологий, разрабатывающей технологии анализа и синтеза речи, а также распознавания лиц. До этого разработчик полностью принадлежал Газпромбанку. У Сбербанка уже есть опыт использования разработок ЦРТ в своих продуктах. В частности, на их основе была создана цифровая телеведущая Елена, которую банк представил в апреле 2019 г. До этого в июне 2017 г. Сбербанк начал внедрение разработок компании в собственной биометрической системе защиты информации. Технологии ЦРТ позволяют идентифицировать клиентов банка по голосу, сравнивая его с заранее записанным образцом.
2019. Тинькофф запустил сервисы распознавания и синтеза речи
Недавно Тинькофф банк запустил голосового ассистента Олега, а теперь решил открыть свои API распознавания и синтеза речи для сторонних бизнес-приложений. Например, их можно использовать для создания ботов, смарт-автоответчиков колл-центра, записи IVR, озвучки видеороликов, перевода звуковых записей телефонных разговоров или совещаний в текстовый формат. Стоимость Tinkoff VoiceKit составляет 40-45 копеек за распознавание минуты двухканального аудио, в планах также ввести посекундную тарификацию. Стоимость синтеза речи банк пока не определил. Для сравнения, тариф на распознавание речи с помощью технологии SpeechKit от Яндекса составляет 60 копеек за минуту.